This article was last updated on <span id="expire-date"></span> days ago, the information described in the article may be outdated.
最近想要将导师的WRF工具包里的一些功能使用Python重写,因为想要使用优雅的方式实现,所以不可避免的涉及到了GRIB文件的读写。花了两天时间摸清楚了如何将数据写入GRIB文件,期间还遇到一些比较奇怪的问题。
使用cfgrib将数据写入GRIB文件
GRIB文件的读取是比较简单的,使用cfgrib.open_dataset或者cfgrib.open_datasets就可以将GRIB文件中的grib message读取成xarray.Dataset的格式。
但是GRIB文件的写入比较麻烦,需要设置一大堆的参数。通过查看cfgrib读取的数据,可以看到attrs里面有众多以GRIB_开头的属性,这里以我下载的ERA5 surface数据为例。
1 | import cfgrib as cf |
1 | {'Conventions': 'CF-1.7', |
这些GRIB_开头的属性即从GRIB文件中转换得到的参数,也是想把数据写成GRIB文件时所需要设置的参数。其中有一些参数是非常关键的:
GRIB_centre:GRIB文件只记录了编码后的信息,解码时需要对照码表文件将文件中的编码翻译为对应的信息,而不同的机构会有自己定义的码表。GRIB_centre这个参数即定义了编码和解码时使用哪个机构定义的码表。所有机构的定义可以在这里查阅。GRIB_edition:GRIB文件有GRIB1和GRIB2两个版本,这两个版本间存在字段定义的区别,设置不同的版本会导致文件记录的信息不一致,这个问题稍后会提到。GRIB_paramId:记录的变量对应的ID号,可以在这里查看ECMWF所有的ID定义。
也有一些参数是不用手动设置的:
GRIB_missingValue:无论你定义的值是多少,cfgrib软件包内部都会将这个数值重新设置
要想保证数据准确无误的写进GRIB文件,其他参数当然也是必不可少的,但是这里就不再展开说明了。
下面直接以一个示例来说明,如何将数据写入GRIB文件。
1 | import cfgrib as cf |
1 | (array([], dtype=int64), array([], dtype=int64), array([], dtype=int64)) |
numpy的输出表示读出的数据都是相同的,同时可以看到解码得到的属性值与我们设置的是相同的,同时cfgrib还为我们添加了一些对应属性的设置,例如GRIB_centreDescription,history,GRIB_missingValue等。
坑人的问题
前面说道,GRIB_edition设置不同的版本会导致文件记录的信息不一致,起初我还以为这是cfgrib或者eccodes的bug,但是后来才发现是我对GRIB理解不足导致的。直接来看代码。
还是使用上面的例子定义的data_array变量,只不过这次我们对dataset.attrs的设置有所不同。
1 | dataset = Dataset({ |
这两个dataset写入GRIB以后,读取出来的信息是不一样的。
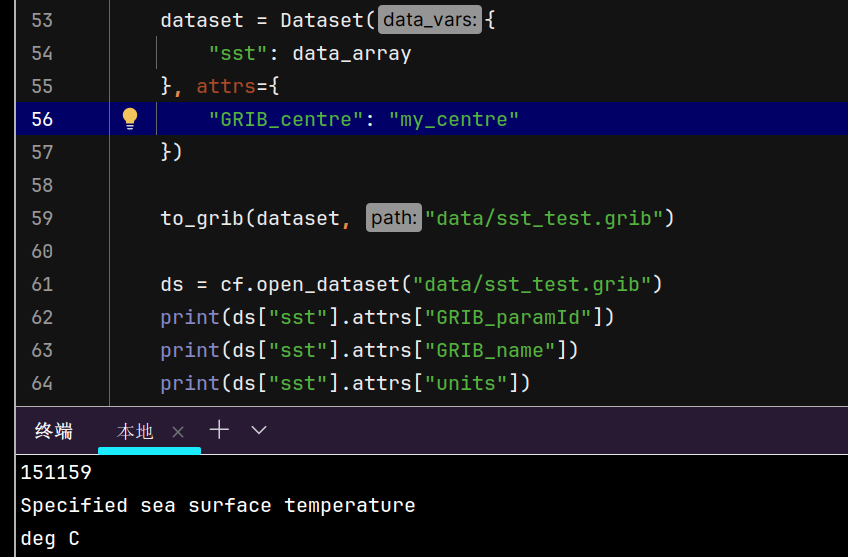
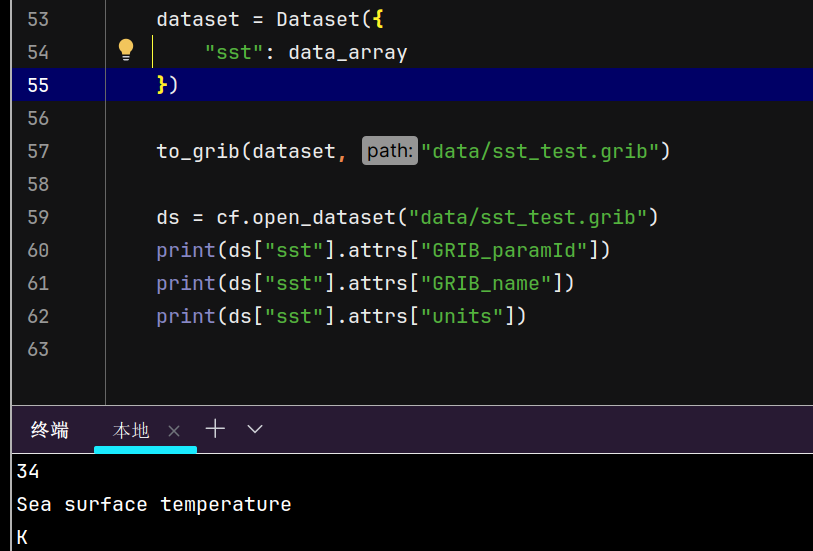
一开始我是想自定义GRIB_centre的名称的,因为我并没有想到GRIB_centre会影响到文件的解码,所以了解了GRIB_centre的用途之后,自然也就想到了这有可能是GRIB_centre设置不正确影响的,但其实不是的。my_centre并不是一个有效的机构名称,cfgrib会自动进行纠正。
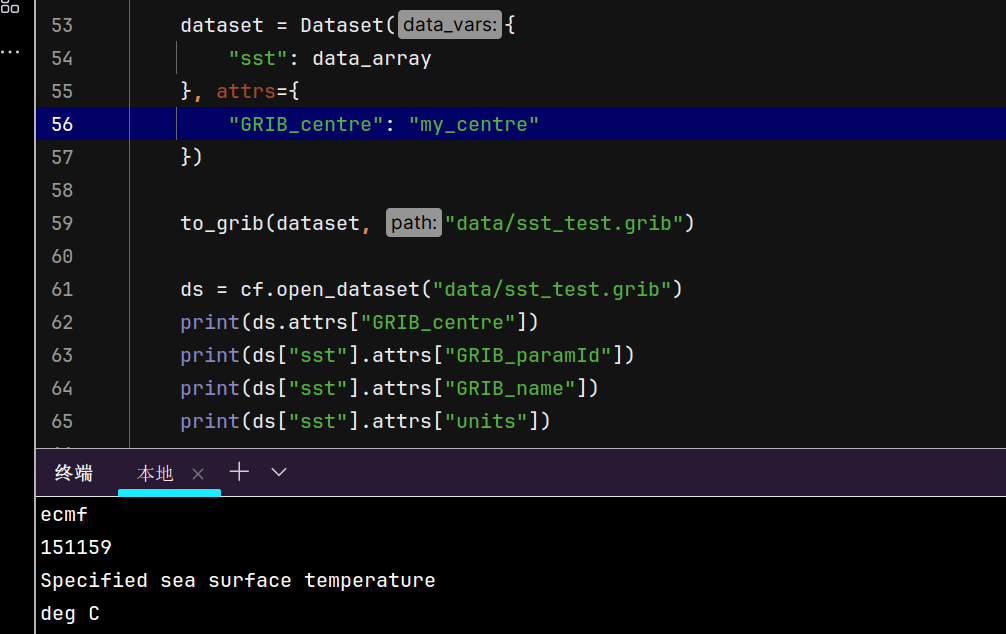
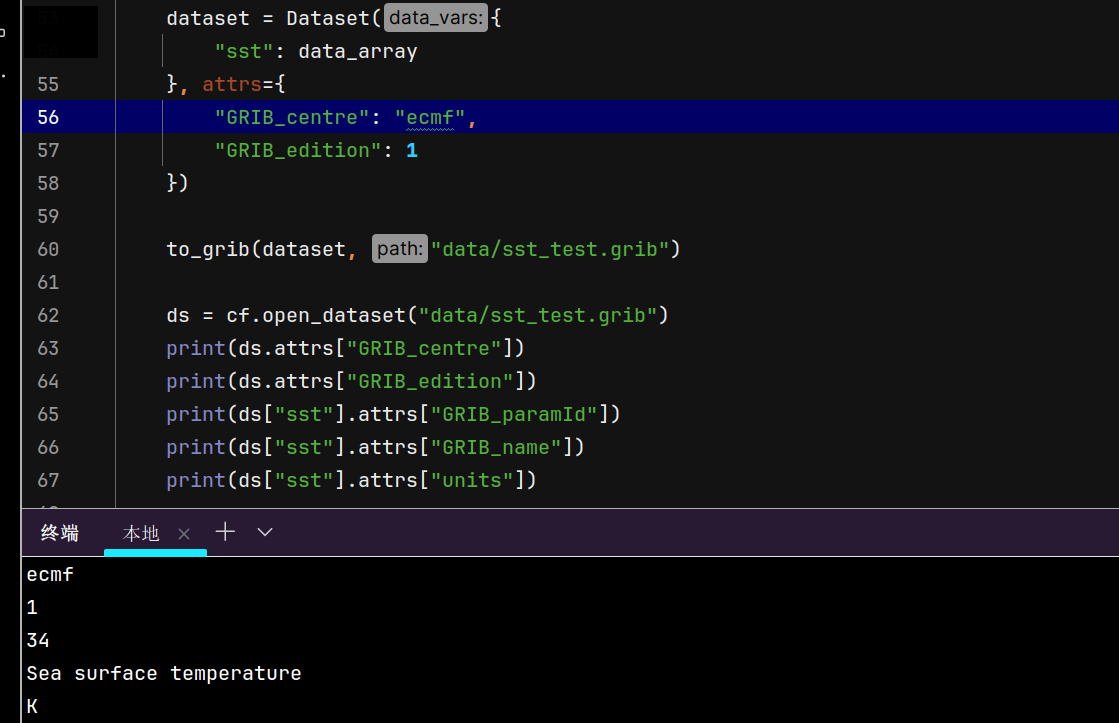
ecmf也是我下载的数据中GRIB_centre的设置,这说明并不是GRIB_centre导致的这个不同。这其实是GRIB_edition设置导致的,缺省情况下,cfgrib会以GRIB2的格式来写数据,而GRIB2和GRIB1的差异导致了我们写入和读取出的信息的不同,手动设置版本为1后,这个问题就可以解决了。当然为了规范期间,GRIB_centre还是设置一个有效的名称更好。
Author: Syize
Permalink: https://blog.syize.cn/2024/09/23/write-grib-with-cfgrib/
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Syizeのblog!
Comments