在我为组里写的海雾反演工具包中,有一个葵花卫星数据下载的函数。因为葵花卫星数据是通过FTP方式下载的,而Python的requests库又不支持FTP协议,所以只好借助了pycurl来下载数据。
最近葵花数据的下载异常的慢,而pycurl似乎没有多线程下载的功能(我在撰写这篇发现pycurl中有一个CurlMulti对象,似乎可以通过该对象实现在一个Python进程中同时下载多个数据片段),pycurl对多线程的支持也不好,无奈只能自己想办法实现多进程下载的功能了。
原始的下载代码实现起来非常简单,调用setopt()函数依次设置好各个参数就可以下载数据了。这里只放出核心的代码部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 CURL.setopt(pycurl.URL, ftp_url) CURL.setopt(pycurl.NOPROGRESS, False ) CURL.setopt(pycurl.XFERINFOFUNCTION, ftp_callback) if exists(f"{save_path} /{temp_filename} " ): open_type = "ab" file_size = getsize(f"{save_path} /{temp_filename} " ) CURL.setopt(pycurl.RESUME_FROM, file_size) ftp_callback.set_start_size(file_size) else : open_type = "wb" with open (f"{save_path} /{temp_filename} " , open_type) as f: CURL.setopt(pycurl.WRITEDATA, f) try : CURL.perform() except pycurl.error as e: logger.error(f"Failed to download data: {ftp_url} " ) logger.error(f"Error occurred: {e} " ) return False
这里为了能够回报下载进度,我使用了自定义的ftp_callback对象作为回调函数,下载之前先判断临时文件是否已经存在,存在的话就断点续传,避免重复下载。
pycurl有个不好的地方,就是它的错误处理很丑。无论是哪种类型的错误,它都会捕获,然后抛出自己的pycurl.error,这里我们不考虑下载重试的功能,所以错误的类型暂时没有影响,有错误就直接返回False。
多进程版本的实现原理是,首先获取文件大小信息,然后根据使用的进程数,计算得到每个进程需要下载的起点和终点,并使用multiprocessing分段下载文件。下载完成后,再合并。
获取文件的大小可以通过设置NOBODY来只获取头信息,但是pycurl会强制打印出两行信息出来,没办法控制不输出。
1 2 3 4 5 6 7 curl = pycurl.Curl() curl.setopt(pycurl.URL, self .url) curl.setopt(pycurl.NOPROGRESS, True ) curl.setopt(pycurl.NOBODY, 1 ) curl.perform() file_size = int (curl.getinfo(pycurl.CONTENT_LENGTH_DOWNLOAD))
获取到文件之后,就可以计算出每个进程所需要下载的文件范围,然后起子进程开始下载。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 process_num = 6 chunk_size = file_size // process_num process_pool = [] recv_pipe, send_pipe = Pipe(False ) for (i, _part_filename) in enumerate (part_filenames[:-1 ]): process_pool.append( Process( target=self .multiple_process, args=[_part_filename, chunk_size * i, chunk_size * (i + 1 ) - 1 , send_pipe] ) ) process_pool[i].start() process_pool.append(Process( target=self .multiple_process, args=[part_filenames[-1 ], chunk_size * (process_num - 1 ), file_size, send_pipe] )) process_pool[-1 ].start()
为了能够在多进程的情况下也能回报进度,这里使用multiprocessing的Piep创建了一个管道,send_pipe分发给所有的子进程,用于回报下载进度。子进程启动后,需要轮询子进程的状态,在正常下载完毕或者子进程异常退出时做出相应的处理。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 loop_flag = 1 stop_flag = 0 while loop_flag: status_code = [] for _process in process_pool: if pid is not None : if recv_pipe.poll(): progress.update(pid, advance=recv_pipe.recv()) if _process.is_alive(): status_code.append(0 ) elif _process.exitcode != 0 : status_code.append(1 ) else : status_code.append(2 ) if 1 in status_code: loop_flag = 0 stop_flag = 1 elif 0 not in status_code: loop_flag = 0 if stop_flag: for _process in process_pool: if _process.is_alive(): _process.terminate() return False else : ...
这里我们在轮询的过程中顺便通过recv_pipe接收下载进度回报,更新进度。
如果有子进程异常退出(exitcode != 0),则直接退出轮询,然后停止掉所有其他正在运行的子进程,结束本次下载。
在每个进程的内部,pycurl的使用方式和单进程版本没有区别,只不过多了一步设置文件下载范围的步骤。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def multiple_process (self, part_filename: str , start: int , end: int , send_pipe: Connection ): curl = pycurl.Curl() curl.setopt(pycurl.URL, self .url) curl.setopt(pycurl.NOPROGRESS, False ) save_path = f"{self.save_path} /{part_filename} " if exists(save_path): downloaded_size = getsize(save_path) if downloaded_size > (end - start): open_type = "wb" else : open_type = "ab" start = start + downloaded_size else : downloaded_size = 0 open_type = "wb" curl.setopt(pycurl.RANGE, f"{start} -{end} " ) curl.setopt(pycurl.XFERINFOFUNCTION, CurlMultiProcessCallback(send_pipe, downloaded_size)) with open (save_path, open_type) as f: curl.setopt(pycurl.WRITEDATA, f) curl.perform()
这里自定义了一个CurlMultiProcessCallback类作为回调函数,使用分配的send_pipe发送每次新写入的文件大小来汇报下载进度。
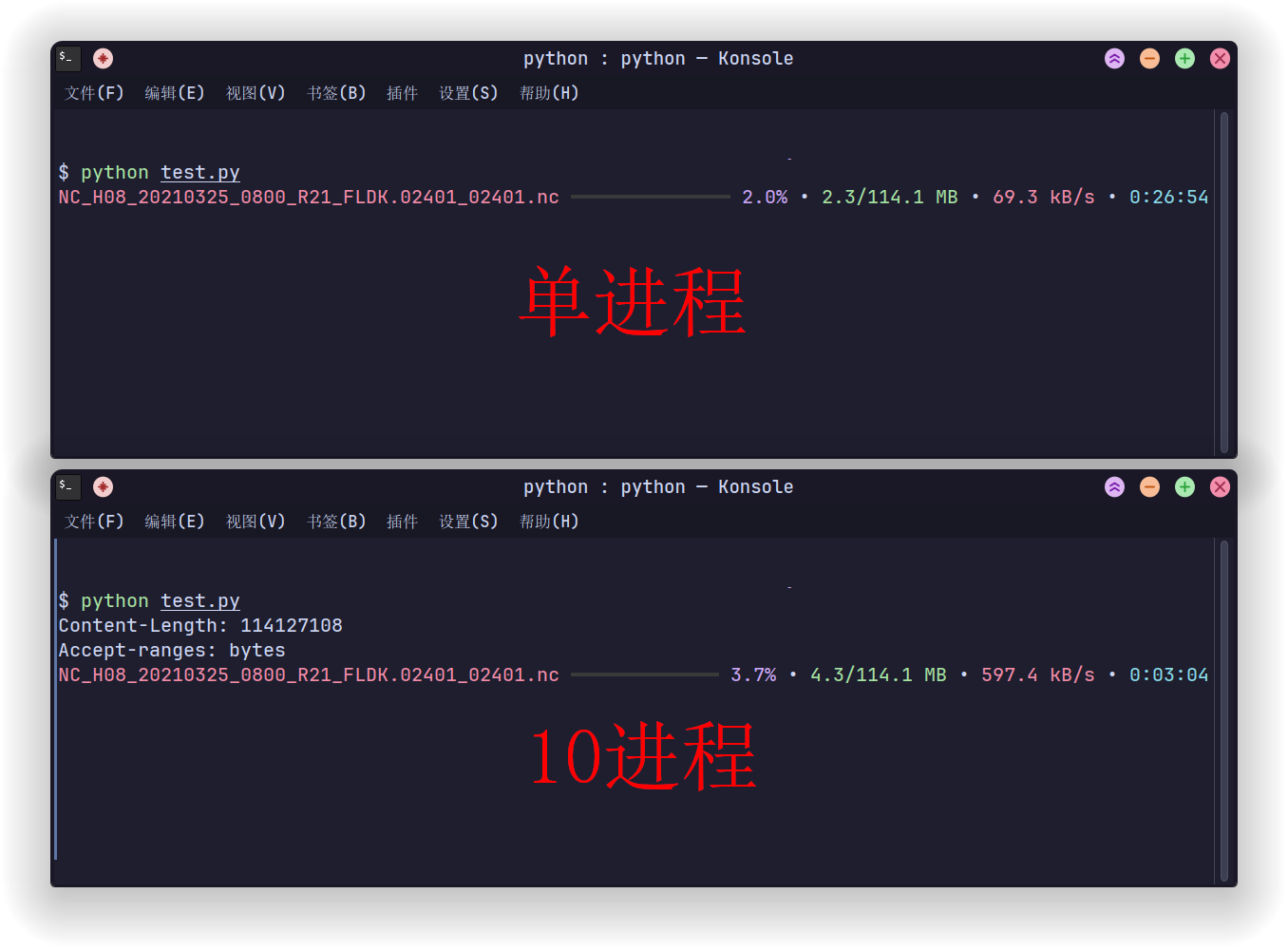
最后贴一张单进程和多进程下载的对比图
Comments